Neural Style Transfer, Part 1
I’ve recently read about how Neural Style Transfer works on images in Medium and decided to play around with it. (I know this paper is old, but even it was a pleasant experience anyways)
What is Neural Style Transfer?
For those who don’t know what Neural Style Transfer is, it is a technique in which we use a pre-trained Convolutional Neural Network (CNN) to optimise an image given some constraint target images. That is: We transform an image by making it look like other images, but for one of those we want to look similar in content and for the other in style.
How Does it Work? (Edited in 22/06/2019)
The CNN builds up levels of more refined representations over its layers and, by selecting the values of these intermediate representations for different input images and comparing them, we can tell how much apart they are from each other. We’ll say that the internal representation of the CNN at layer for an input image is . We’ll use to represent the image we are optimising, for the image we want to look similar in content and for the one we want to have the style of.
In the paper, there are two types of differences with which the Authors are concerned, what they call a content difference and a style difference. They define that the content difference can simply be calculated as the difference between the internal representation for each of these images. The content difference is based on the simplest metric available: the squared difference. So, we calculate the content difference at layer as:
The authors do this on high-level filters in the network. Assuming that CNNs builds abstractions over its layers and that the first layers represent low-level concepts (such as lines, textures, etc) while the last layers represent higher-level concepts (as noses, houses, eyes, etc) we can interpret this loss, if taken at later layers, as minimising the difference between the concepts present in the image. That is, for each group of pixels in the generated image, we want that the level of “cat-ness” in those pixels is the same than that in the content image.
And now comes the tricky part, how are we supposed to find how close stylistically two images are from each other? The paper uses a concept called a Gram matrix. Each layer in the CNN has a certain number of features , and a certain number of “pixel” , so that for every layer we have the a vectorised feature map . We’ll define the Gram matrix as being the inner product of the vectorised feature map and its transposition:
or
What this is doing is that it captures texture information through the correlation in the filters. By doing this in multiple layers of the CNN, we can obtain texture information on different scales. The distance between the generated image and the style image is calculated as the distance between the Gram matrix of both in these selected layers.
Since the gram matrix is a rudimentary form of correlation between the filters in the whole image, without the spatial information, we can interpret it in the same vein as we interpreted the content loss. The correlation between the filters here can be seen as a way to check if co-ocurring features in the style image also co-occur in the target image. For example, in some paintings of Pablo Picasso, he represented human beings with geometric figures, so we need to adapt our generated image to have this same co-occurence to match Picasso’s style.
Gimme the Code!
I’ve implemented it in Pytorch, set up some style images, and started experimenting with it. If there is any difficulty understanding the code contact me and I’ll expand this section.
Results and Discussion
To test my style transfer implementation I used some friends’ photos and photos of my dog as content photos:






I felt quite satisfied at first when doing the iconic transfer to Van Gogh’s starry night’s style, but after experimenting it with other images, I noticed that it taking the texture into account seemed flawed to me as a definition of style. For example, when working with Van Gogh’s paintings which have highly characteristic textures, the results are often amazing:






But when working with some images whose texture isn’t as well defined, and where the style relies more heavily on the color map or composition, such as when I used the cover for Aesthesys’ album Achromata, the style transfer often fails (my friend liked it anyways):
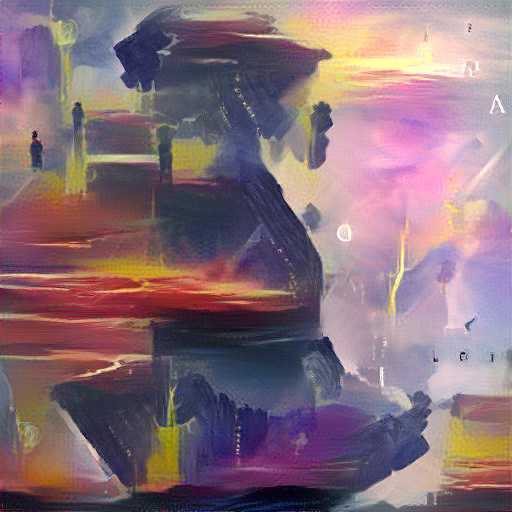

Even so, my initial intentions with style transfer would be satisfied if not for one thing: This technique requires one to perform gradient descent on an image, instead of generating an image based on references. I wanted to perform a Van Gogh restylisation of a game as a real time shader, which is impossible given the current set-up.
In any case, it still produced some cool results, such as the ones below:
Style: Gurdish Pannu

Style: Iberê Camargo

Style: Edvard Munch

{kind=link}
Style: Claude Monet (Used Grainstacks, Grand Canal and Woman with a Parasol)

Style: Henri Matisse

{kind=link}
Style: Pablo Picasso

Style: Cândido Portinari

Style: Paul Signac
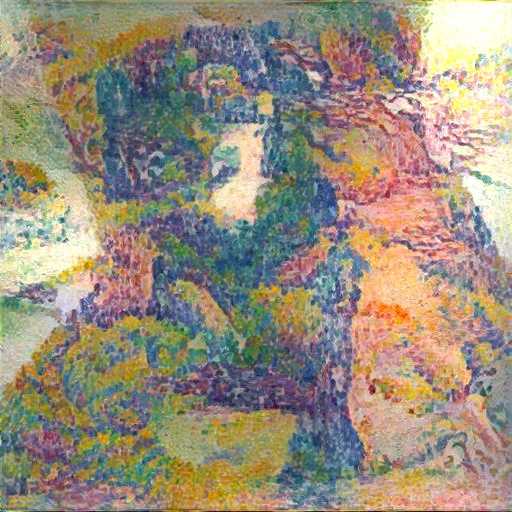
{kind=link}

Conclusions
Style transfer is an interesting technique and even after realising it works mainly by copying textures I still found it interesting. The Medium article authors pointed out a study on how to better tune style transfer to suit an artist’s need and when properly tuned, the results can still be stunning. Still, I was unsatisfied with the lack of a real-time, single-pass network that could produce similar results.
I mused for a while and settled that my next steps would be to train something along the lines of a GAN (Generative Adversarial Network), to be capable of performing style transfer. I settled on some details but, of course, someone had already done something like it. Still, I believe I’ll come to play with this idea later and try to produce a similar solution or reproduce this other paper.
Another thing that I noticed is how style transfer and Inceptionism are similar in the principles of performing gradient descent on the input by optimising some metric on the output values of the network. The results are, to a certain extent, also visually similar, with many inceptionist-generated images being full of texture overlays of dogs ears and noses on the seed image, when optimised to maximise the likelihood of a dog. This similarity is better seen here with the image with the “style” of Cândido Portinari, where there are some phantasmagoric eyes and faces to be seen overlayed over the original picture.